" width="45.999997677181966px"><path d="M 12.719 15.937 C 12.719 16.646 12.254 16.994 11.294 16.994 L 9.629 16.994 L 9.629 13.071 L 11.294 13.071 C 12.243 13.071 12.719 13.425 12.719 14.128 Z M 11.832 14.128 C 11.832 13.707 11.651 13.53 11.19 13.53 L 10.511 13.53 L 10.511 16.541 L 11.19 16.541 C 11.656 16.541 11.832 16.369 11.832 15.937 Z M 16.062 16.994 L 15.865 16.092 L 15.865 16.115 L 14.451 16.115 L 14.451 16.092 C 14.385 16.38 14.303 16.707 14.243 16.994 L 13.563 16.994 L 14.555 13.071 L 15.953 13.071 L 17.021 16.994 Z M 15.3 13.497 L 14.999 13.497 L 14.55 15.661 L 15.777 15.661 L 15.306 13.497 Z M 19.257 13.525 L 19.257 16.994 L 18.364 16.994 L 18.364 13.525 L 17.536 13.525 L 17.536 13.071 L 20.09 13.071 L 20.09 13.525 L 19.263 13.525 Z M 22.94 16.994 L 22.742 16.092 L 22.742 16.115 L 21.329 16.115 L 21.329 16.092 C 21.263 16.38 21.181 16.707 21.12 16.994 L 20.441 16.994 L 21.433 13.071 L 22.83 13.071 L 23.899 16.994 Z M 22.183 13.497 L 21.882 13.497 L 21.433 15.661 L 22.66 15.661 L 22.189 13.497 Z M 28.99 16.967 L 28.546 16.967 C 28.409 16.967 28.283 16.95 28.179 16.917 C 28.075 16.884 27.981 16.823 27.905 16.729 L 27.762 16.568 C 27.466 16.856 27.121 17 26.732 17 C 26.343 17 26.074 16.911 25.839 16.74 C 25.603 16.568 25.488 16.325 25.488 16.009 C 25.488 15.694 25.554 15.605 25.68 15.412 C 25.806 15.218 26.009 15.069 26.294 14.941 C 26.168 14.781 26.08 14.637 26.03 14.521 C 25.987 14.399 25.959 14.261 25.959 14.1 C 25.959 13.94 26.009 13.768 26.102 13.624 C 26.2 13.48 26.332 13.37 26.496 13.292 C 26.661 13.209 26.853 13.171 27.061 13.171 C 27.269 13.171 27.401 13.209 27.543 13.281 C 27.685 13.353 27.801 13.458 27.883 13.586 C 27.965 13.713 28.009 13.862 28.009 14.023 C 28.009 14.183 27.943 14.427 27.812 14.598 C 27.68 14.77 27.455 14.919 27.132 15.052 L 27.817 15.799 L 28.371 14.936 L 28.946 14.936 L 28.135 16.153 L 28.305 16.341 C 28.349 16.397 28.398 16.43 28.442 16.447 C 28.486 16.463 28.546 16.474 28.612 16.474 L 28.973 16.474 L 28.973 16.972 Z M 26.584 15.262 L 26.573 15.251 C 26.398 15.345 26.272 15.445 26.195 15.55 C 26.124 15.655 26.085 15.783 26.085 15.937 C 26.085 16.092 26.146 16.264 26.272 16.364 C 26.398 16.463 26.562 16.519 26.765 16.519 C 26.968 16.519 27.247 16.419 27.455 16.225 L 26.579 15.262 Z M 26.546 14.078 C 26.546 14.194 26.568 14.294 26.611 14.382 C 26.655 14.471 26.737 14.582 26.853 14.715 C 27.258 14.543 27.461 14.311 27.461 14.023 C 27.461 13.735 27.422 13.796 27.346 13.718 C 27.269 13.641 27.165 13.602 27.039 13.602 C 26.913 13.602 26.776 13.646 26.683 13.735 C 26.589 13.824 26.546 13.94 26.546 14.073 Z M 33.029 16.994 L 32.831 16.092 L 32.831 16.115 L 31.417 16.115 L 31.417 16.092 C 31.352 16.38 31.269 16.707 31.209 16.994 L 30.53 16.994 L 31.522 13.071 L 32.919 13.071 L 33.988 16.994 Z M 32.267 13.497 L 31.965 13.497 L 31.516 15.661 L 32.744 15.661 L 32.272 13.497 Z M 34.996 16.994 L 34.996 13.071 L 35.889 13.071 L 35.889 16.994 Z M 18.808 0.105 C 18.742 0.055 18.665 0.022 18.583 0.022 L 13.043 0.022 C 12.949 0.022 12.856 0.061 12.791 0.127 L 11.799 1.14 C 11.733 1.206 11.695 1.295 11.695 1.389 L 11.695 7.421 C 11.695 7.526 11.744 7.631 11.826 7.698 L 14.259 9.706 C 14.325 9.756 14.402 9.789 14.484 9.789 L 20.024 9.789 C 20.117 9.789 20.211 9.751 20.276 9.684 L 21.268 8.672 C 21.334 8.605 21.372 8.517 21.372 8.423 L 21.372 2.391 C 21.372 2.285 21.323 2.18 21.241 2.114 Z M 14.358 6.995 L 14.358 2.828 C 14.358 2.629 14.517 2.468 14.714 2.468 L 18.358 2.468 C 18.556 2.468 18.715 2.629 18.715 2.828 L 18.715 6.995 C 18.715 7.194 18.556 7.354 18.358 7.354 L 14.714 7.354 C 14.517 7.354 14.358 7.194 14.358 6.995 Z M 33.779 7.349 L 33.346 7.349 C 33.155 7.349 33.001 7.194 33.001 7 L 33.001 2.385 C 33.001 2.28 32.957 2.18 32.875 2.114 L 30.436 0.1 C 30.376 0.05 30.299 0.022 30.217 0.022 L 24.666 0.022 C 24.573 0.022 24.485 0.061 24.419 0.127 L 23.422 1.146 C 23.356 1.212 23.323 1.3 23.323 1.389 L 23.323 7.432 C 23.323 7.537 23.367 7.637 23.449 7.703 L 25.888 9.717 C 25.948 9.767 26.025 9.795 26.107 9.795 L 34.585 9.795 C 34.777 9.795 34.93 9.64 34.93 9.446 L 34.93 8.66 C 34.93 8.577 34.903 8.5 34.848 8.434 L 34.031 7.471 C 33.966 7.393 33.873 7.349 33.768 7.349 Z M 25.992 7 L 25.992 2.811 C 25.992 2.618 26.146 2.463 26.337 2.463 L 30.004 2.463 C 30.195 2.463 30.349 2.618 30.349 2.811 L 30.349 7 C 30.349 7.194 30.195 7.349 30.004 7.349 L 26.337 7.349 C 26.146 7.349 25.992 7.194 25.992 7 Z M 34.47 0.354 L 34.47 2.136 C 34.47 2.319 34.618 2.468 34.799 2.468 L 38.98 2.468 C 39.161 2.468 39.309 2.618 39.309 2.8 L 39.309 9.463 C 39.309 9.646 39.457 9.795 39.638 9.795 L 41.643 9.795 C 41.824 9.795 41.972 9.646 41.972 9.463 L 41.972 2.606 C 41.972 2.518 41.939 2.435 41.873 2.374 L 39.649 0.127 C 39.588 0.066 39.506 0.028 39.418 0.028 L 34.804 0.028 C 34.623 0.028 34.475 0.177 34.475 0.36 Z M 41.89 0.343 L 41.89 2.269 C 41.89 2.38 41.978 2.468 42.087 2.468 L 45.688 2.468 C 45.863 2.468 46 2.324 46 2.153 L 46 0.343 C 46 0.166 45.858 0.028 45.688 0.028 L 42.202 0.028 C 42.027 0.028 41.89 0.172 41.89 0.343 Z M 9.815 1.162 L 8.757 0.094 C 8.697 0.033 8.615 0 8.533 0 L 0.318 0 C 0.142 0 0 0.144 0 0.321 L 0 9.452 C 0 9.629 0.142 9.773 0.318 9.773 L 2.356 9.773 C 2.532 9.773 2.674 9.629 2.674 9.452 L 2.674 6.369 C 2.674 6.192 2.817 6.049 2.992 6.049 L 7.152 6.049 C 7.327 6.049 7.469 6.192 7.469 6.369 L 7.469 9.452 C 7.469 9.629 7.612 9.773 7.787 9.773 L 9.453 9.773 C 9.629 9.773 9.771 9.629 9.771 9.452 L 9.771 7.393 C 9.771 7.31 9.738 7.227 9.678 7.166 L 8.319 5.794 C 8.193 5.667 8.193 5.467 8.319 5.34 L 9.815 3.829 C 9.875 3.769 9.908 3.686 9.908 3.603 L 9.908 1.395 C 9.908 1.312 9.875 1.229 9.815 1.168 Z M 2.674 3.591 L 2.674 2.651 C 2.674 2.474 2.817 2.33 2.992 2.33 L 7.152 2.33 C 7.327 2.33 7.469 2.474 7.469 2.651 L 7.469 3.591 C 7.469 3.769 7.327 3.912 7.152 3.912 L 2.992 3.912 C 2.817 3.912 2.674 3.769 2.674 3.591 Z" fill="rgb(0, 0, 0)" height="17.000000317891438px" id="d8Kh67i7I" width="45.999997677181966px"/></g></svg>)
Como evitar que dados ruins contaminem decisões estratégicas
ROQT | Data & AI

Compartilhe
Dados ruins deixam de contaminar decisões quando a empresa define uma fonte única para cada indicador, atribui responsáveis pela qualidade das informações, valida os dados na origem e monitora inconsistências de forma contínua.
Sem esses controles, qualquer número que chega à diretoria pode carregar erros que ninguém consegue rastrear até a causa.
O problema raramente aparece com esse nome na rotina de quem decide, ele aparece como uma reunião em que duas áreas apresentam números diferentes para a mesma pergunta, como um relatório refeito três vezes antes de subir para a diretoria, ou como uma decisão de preço tomada sobre uma margem que, semanas depois, se revelou calculada errado.
Definição
Qualidade de dados é o grau de precisão, consistência, completude e atualidade das informações que uma empresa usa para decidir. Um dado tem qualidade quando reflete a realidade da operação e chega íntegro a quem precisa dele no momento da decisão.
Por que dados ruins chegam até a diretoria sem ninguém perceber?
Porque o erro nasce na origem e se esconde no caminho.
Um cadastro duplicado no CRM, uma fórmula quebrada em planilha ou uma integração que falhou de madrugada produzem números que parecem normais quando consolidados em um relatório, e quem apresenta o número quase nunca conhece o trajeto que ele percorreu até a tela.
A maioria das empresas só valida o dado no destino, quando ele já virou indicador.
Nesse ponto, a checagem se resume a comparar o número com a expectativa de quem lê, se o resultado parece razoável, ninguém questiona, se parece estranho, abre-se uma investigação manual que consome dias de trabalho de analistas e nem sempre encontra a causa.
Existe ainda um fator estrutural, onde cada área constrói os próprios relatórios com as próprias regras de cálculo, por exemplo a receita, para o comercial, inclui pedidos faturados, enquanto para o financeiro inclui apenas o que entrou no caixa.
As duas áreas estão certas dentro da própria lógica, e a diretoria recebe dois números verdadeiros que contam histórias diferentes. É esse tipo de divergência, e não o erro grosseiro, que mais contamina decisões estratégicas, porque ela passa despercebida por meses.
Quanto custa decidir com dados contaminados?
O custo mais visível é o da decisão errada em si, como um preço definido sobre uma margem incorreta ou um estoque dimensionado sobre uma previsão furada. O custo menos visível é o operacional, com analistas gastando a semana conferindo e refazendo números em vez de analisar o negócio.
Os dois se acumulam em silêncio, porque raramente alguém liga o prejuízo lá na frente ao dado errado lá atrás.
Há um terceiro custo, mais difícil de reverter: a perda de confiança.
Quando um diretor descobre que o indicador que ele acompanhava estava errado, ele passa a desconfiar de todos os outros, a partir daí, cada número apresentado precisa ser defendido, cada reunião ganha uma rodada de questionamento sobre a origem do dado, e as decisões voltam a se apoiar na experiência e na intuição de quem grita mais alto.
O investimento feito na área de dados continua no orçamento, mas deixa de influenciar as escolhas que importam.
Qual a diferença entre dado errado e dado inconsistente?
O dado errado não corresponde à realidade, como uma venda lançada com o valor trocado, já o dado inconsistente pode estar correto na origem, mas diverge entre sistemas ou relatórios, como um mesmo cliente com cadastros diferentes no CRM e no ERP.
Os dois contaminam decisões, mas exigem tratamentos distintos.
O erro se combate na entrada, com:
Validação de campos
Padronização de cadastros
Regras que impedem o lançamento incompleto.
A inconsistência se combate na arquitetura, com:
Integração entre sistemas
Definição oficial para cada métrica, registrada e conhecida por todas as áreas.
Empresas que tratam inconsistência como se fosse erro pontual entram em um ciclo de correções manuais que nunca termina, porque a causa estrutural continua intacta.

Como identificar se os dados da empresa são confiáveis?
O teste mais simples é perguntar o mesmo indicador para duas áreas diferentes e comparar as respostas, se os números divergirem, ou se cada área precisar de horas para responder, a empresa tem um problema de confiabilidade.
Confiança em dados se mede pela capacidade de responder rápido e com uma única versão.
Outros sinais aparecem na rotina, como:
Relatórios que dependem de uma pessoa específica para serem gerados
Planilhas paralelas circulando por e-mail como fonte oficial
A frase "deixa eu confirmar esse número" repetida em toda reunião
Decisões adiadas porque ninguém chegou a um consenso sobre qual dado vale.
Nenhum desses sinais costuma ser tratado como um problema de dados, eles são tratados como burocracia natural da empresa, e é exatamente assim que o problema sobrevive.
Como garantir a qualidade dos dados na prática?
A qualidade dos dados depende mais de processo e responsabilidade definida do que de qualquer ferramenta específica.
Os passos abaixo funcionam em empresas de portes diferentes e podem começar pelo conjunto pequeno de indicadores que sustenta as decisões mais caras.
Mapeie a origem de cada indicador crítico: documente de onde vem cada número que a diretoria acompanha, quais sistemas alimentam o cálculo e quem é o dono da regra.
Defina uma fonte única para cada métrica: receita e margem precisam de uma definição oficial, registrada em um dicionário de dados acessível a todas as áreas, para acabar com as versões paralelas.
Valide na entrada: campos obrigatórios, padronização de cadastros e regras de consistência no ERP e no CRM impedem que o erro entre no sistema.
Centralize os dados em um repositório único: um data warehouse ou lakehouse, em plataformas como Databricks ou Microsoft Fabric, consolida as fontes e tira as planilhas paralelas do papel de base de decisão.
Monitore a qualidade de forma contínua: testes automatizados de consistência e alertas para volumes fora do padrão detectam o problema antes que ele apareça no relatório da diretoria.
Atribua responsabilidade formal: cada domínio de dado precisa de um dono com autoridade para corrigir a origem, e a empresa precisa de alguém que responda pela governança como um todo.
Quem deve ser o responsável pela qualidade dos dados?
A responsabilidade se divide em dois níveis, quem gera o dado responde pela entrada correta, e a área de dados responde pelos controles, pela integração e pelo monitoramento contínuo.
Sem essa divisão formalizada, a qualidade vira tarefa de todos e prioridade de ninguém.
O segundo nível é o que mais falta nas empresas brasileiras. Montar uma área de dados interna exige contratar engenheiros e analistas em um mercado disputado, treinar, reter e ainda dar direção técnica a esse time, e o gestor que tenta resolver qualidade de dados sem essa estrutura acaba delegando o tema para o TI ou para um analista sobrecarregado.
É nesse ponto que parte das empresas opta por operar com uma área de dados externa e contínua. A ROQT funciona como o time de dados completo do cliente, da arquitetura ao monitoramento de qualidade, sem que ele precise contratar e gerir a própria equipe.
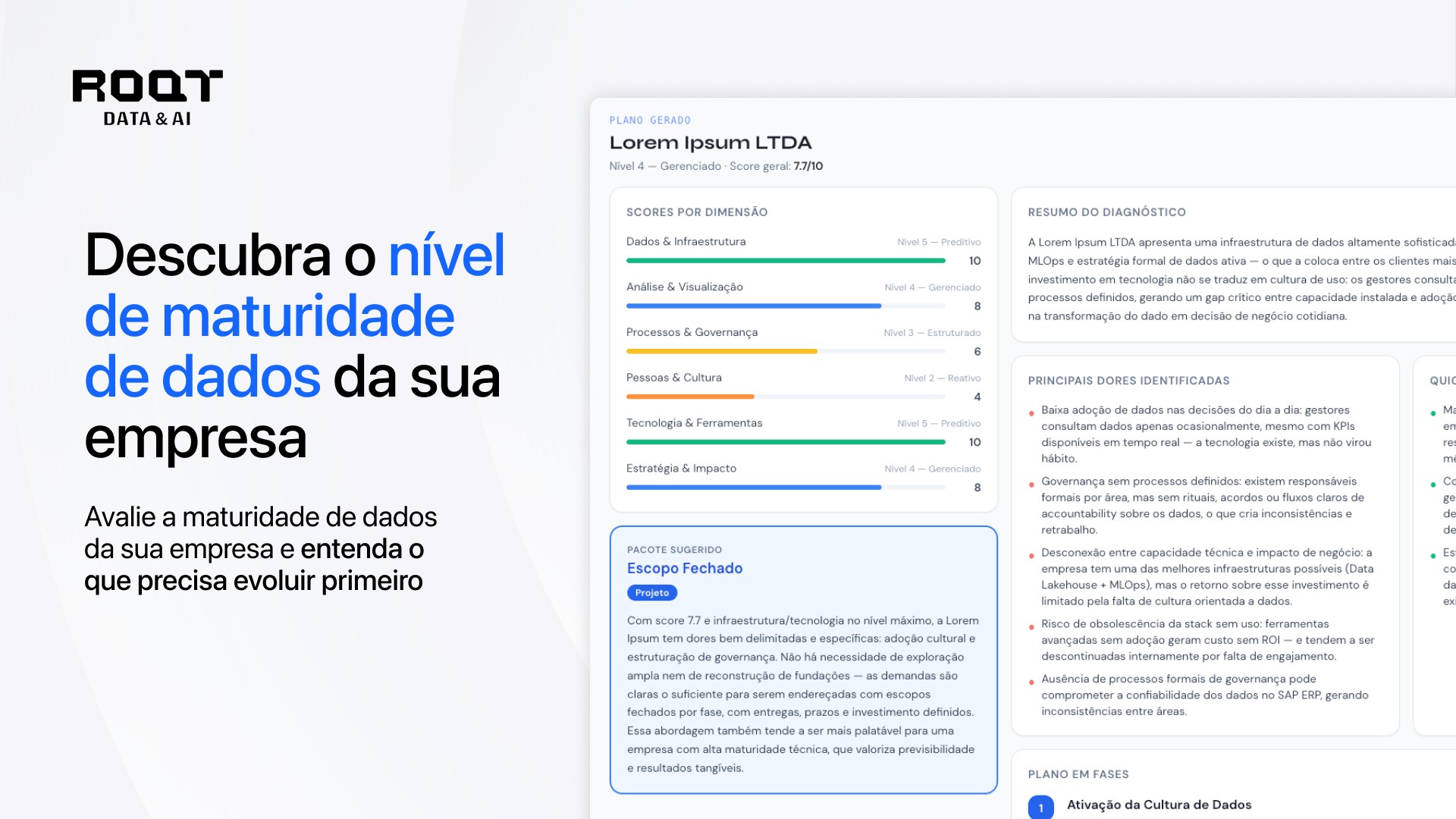
Antes de decidir entre montar time, contratar plataforma ou buscar um parceiro, vale entender em que estágio a sua empresa está hoje.
O diagnóstico de maturidade de dados mostra onde estão as falhas que contaminam as decisões e qual o próximo passo faz sentido para o seu cenário.